Article
What Is a Semantic Terrain?
A Semantic Terrain is a computed reading of a corpus's structural geography. Learn how it differs from RAG, clustering, and scatterplots, and why CAINC generates it as a new category of corpus intelligence.
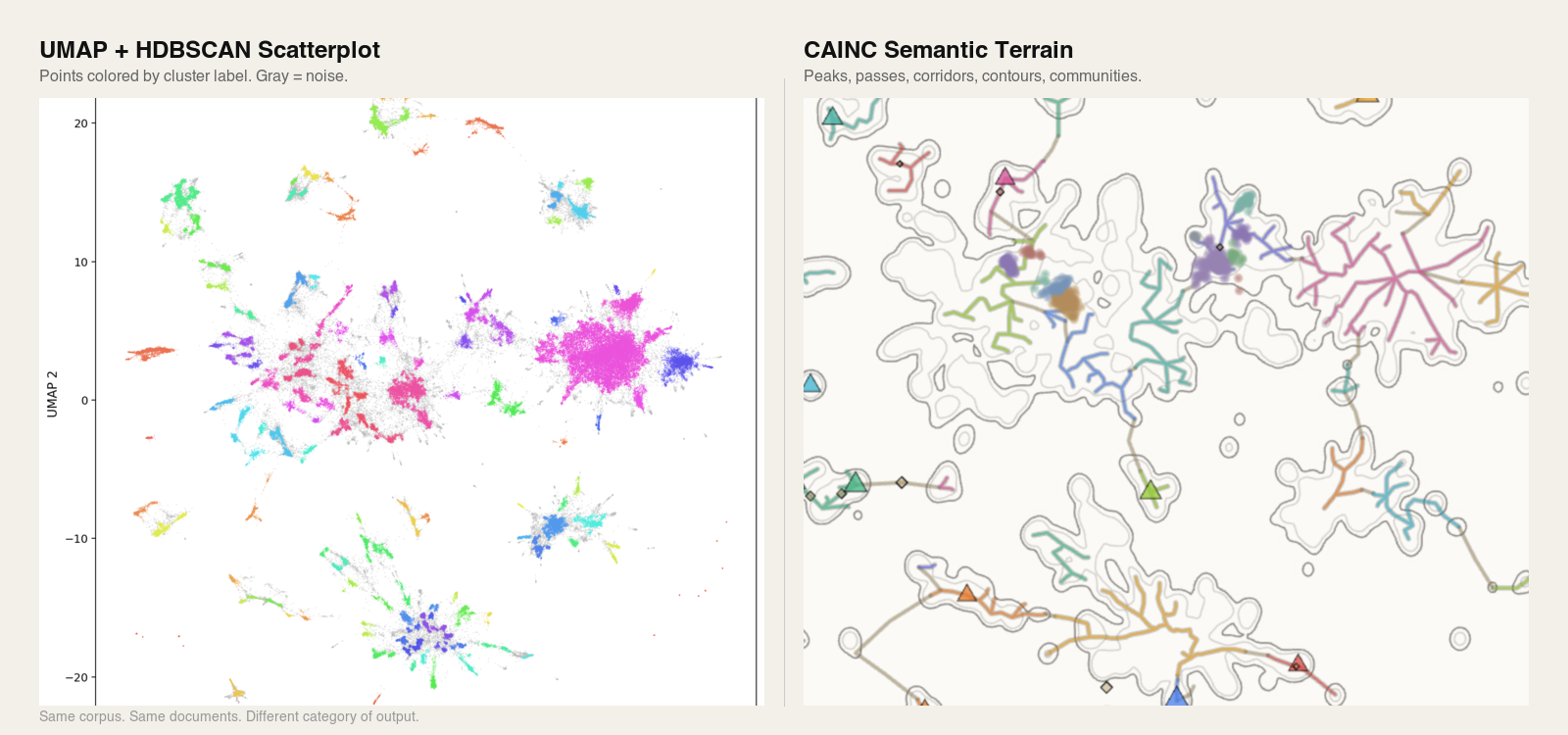
Same corpus. Same documents. The only difference is the instrument that read the data.
TL;DR
- •A Semantic Terrain is a computed, navigable reading of the structural geography of a document corpus, not a visualization, not a cluster list, not a retrieval result.
- •RAG finds needles; scatterplots distort distances; clustering flattens geography. A Semantic Terrain measures the whole haystack as navigable landform.
- •Terrain features (peaks, passes, corridors, contours, communities, skeletons) are first-class objects you can navigate and query.
- •Terrain-Augmented Generation (TAG) retrieves across terrain structure rather than document chunks alone.
If RAG finds a needle in a haystack, what measures the haystack?
That question names the gap a Semantic Terrain is built to fill. Retrieval-Augmented Generation is very good at pulling relevant passages once you know what to ask. It cannot tell you what the corpus is about, where the dense thematic regions are, which topics are bridging into one another, or what is structurally emerging before anyone has thought to query it. It finds needles. It never measures the haystack.
A Semantic Terrain is the measurement.
Formally: a Semantic Terrain is a topological representation of a document corpus, derived from a continuous scalar field of embedding densities, from which a navigable topographic map (peaks, passes, corridors, contours, and communities) is extracted as a structure of first-class objects.
That object is not a visualization, not a cluster list, not a ranked result set, and not a repackaged scatterplot. It is a readable geography, with peaks, passes, corridors, contours, and communities, extracted from the corpus itself rather than from any question asked of it. It is produced by CAINC, the SemanticGaps instrument for topological corpus intelligence.
This post explains what a Semantic Terrain is, how it differs from the three tools it is most often mistaken for (retrieval-augmented generation, scatterplot projections, and clustering algorithms), and why that difference constitutes a new paradigm rather than an incremental improvement.
The three tools a Semantic Terrain is not
Most systems that work on document corpora today do one of three things. They retrieve relevant passages in response to a query. They reduce embeddings to two dimensions and plot the result. They group similar documents into clusters. Each of these tools is useful. None of them reads the corpus as a structural whole.
What RAG does, and what it cannot do
RAG, or Retrieval-Augmented Generation, grounds a language model's output in retrieved evidence. The user asks a question. The system searches a vector index, returns the most similar chunks, and passes them to the model as context. The model then generates an answer constrained by that evidence. This is a genuine advance over models operating on parametric memory alone, and for scoped question-answering it works.
But RAG is reactive and fragment-first. It presumes the user already knows what to ask. It treats the corpus as a pile of independent chunks ordered only by their distance from a query vector. It has no representation of the corpus as a whole: no notion of where the thematic centers are, how topics relate, where boundaries form, or what is changing across the document body over time.
The field has begun to say this out loud. In a widely cited 2024 experience report across three production RAG deployments spanning research, education, and biomedical domains, Barnett et al. catalogued seven distinct failure points inherent to the architecture, and concluded that the robustness of a RAG system cannot be designed in at the start; it can only be validated in operation (Barnett et al., 2024). Subsequent practitioner analyses have documented retrieval precision degrading as corpus size grows, multi-hop questions breaking the architecture because no single retrieval pass can assemble evidence distributed across documents, and the system answering confidently even when the corpus does not contain the answer.
This is the deeper issue. RAG cannot surface what you did not know to ask. It cannot tell you the shape of the corpus. It cannot tell you which topics are bridging. It cannot tell you what is emerging. It answers; it does not diagnose.
What scatterplots do, and what they conceal
The second common tool is the embedding scatterplot. Run a corpus through an embedding model, reduce the high-dimensional vectors to two dimensions using t-SNE or UMAP, and plot the result. What you get is a picture of points. Islands appear. Gaps appear. Some points sit close together; others sit far apart. It looks like structure.
Much of it is not. In a 2025 review of 136 visual-analytics papers, Jeon et al. found that t-SNE and UMAP are the dominant dimensionality-reduction techniques in the field, appearing in 75 and 31 of those papers respectively, and simultaneously the most frequently misused. Practitioners routinely use these projections to investigate inter-cluster distances, class separability, and cluster density even though the methods are demonstrably unsuitable for those tasks. The authors' interview study found that many practitioners treat these techniques as "immune to criticism" due to their popularity, and that more than forty percent of reviewed papers provided no justification at all for the technique selected (Jeon et al., 2025).
A complementary result published in Nature Communications the same year showed that the problem is not merely human misuse; it is intrinsic to the methods. Liu, Ma, and Zhong introduced a formal framework (the LOO-map) demonstrating that t-SNE and UMAP contain two distinct classes of embedding discontinuity: an overconfidence-inducing discontinuity that embeds overlapping data into artificially well-separated clusters, and a fracture-inducing discontinuity that fragments continuous data into spurious sub-clusters at arbitrary locations. Both distortions are topological in nature and cannot be eliminated by better hyperparameter tuning alone (Liu, Ma, & Zhong, 2025).
A scatterplot also has a more fundamental problem. It is a rendering, not a structure. The space between two visible clusters is blank pixels. You cannot click on it and ask what is there, because the method did not compute anything to be there. There are no passes, no corridors, no contours. There are only points and the gaps between them, which may or may not reflect the underlying geometry.
Scatterplots offer intuition. They do not offer a navigable object.
What clustering does, and what it flattens
The third tool is clustering. K-means, HDBSCAN, and related algorithms assign each document to a group. K-means requires you to specify the number of clusters in advance, assumes clusters are roughly spherical, and forces every document into exactly one partition. HDBSCAN improves on this by finding clusters of varying density, allowing documents to be labeled as noise, and not requiring a predetermined cluster count (Campello, Moulavi, & Sander, 2013). Both produce the same kind of output: a flat list of labels.
A label is not a geography. Clustering tells you that document 4,821 belongs to group 7. It does not tell you where in the terrain group 7 sits, which other groups group 7 borders have, what bridges group 7 to group 12, or whether group 7 is a stable long-standing region or a recent emergence. Transition zones between groups, arguably the most structurally interesting regions of any corpus, are either discarded as noise or absorbed into whichever cluster pulls hardest, with no record that they were contested.
Clustering tells you what belongs together. It cannot tell you how the belonging is arranged in space.
What a Semantic Terrain is
The formal definition above names the output. This section describes how it is built and what it contains. A Semantic Terrain begins with a scalar field, a density function defined over the embedding space of the corpus that assigns a value to every point in the space, not just the points where documents happen to fall. From that field, CAINC extracts structure: critical points, gradients, basins, and the connective tissue between them. The result is a readable landform with the following features.
Peaks are the dominant topic clusters, the conceptual high ground of a corpus. In the live DOJ Semantic Terrain, peaks correspond to major enforcement categories: healthcare fraud, national security, public corruption, and so on. Peaks can contain sub-peaks, which allows navigation from broad categories into finer-grained topics without losing structural context.
Passes are the low points between peaks. They are the transition zones where topics overlap, share language, or shift into one another. Passes are where jurisdiction is contested, where enforcement categories converge, and where the most structurally interesting signals typically live. A pass between two peaks in different communities marks the structural boundary where one institutional focus transitions into another.
Corridors are the traversable paths between connected peaks. Select two peaks, trace the corridor, and you see the documents, entities, and language that bridge them. Corridors turn the terrain into something you can walk rather than only look at.
Contours are computed boundaries between topic regions, derived from the geometry of the language itself rather than from human tagging.
Communities are groups of related peaks that form coherent regions larger than a single peak but smaller than the full corpus. Unlike clusters, which are defined by feature-space proximity and assigned as flat labels, communities are defined by structural adjacency within the terrain: which peaks border which, which share passes, which are connected through corridors. A community is a neighborhood of the geography, not a bucket of similar items. CAINC resolves communities across Community Tiers (continental, regional, and street), which lets analysts move between broad structural regions and fine-grained local neighborhoods without losing context.
The Skeleton is the structural backbone that connects peaks across the terrain. It is the road network of the corpus: which peaks are neighbors, where the natural transit paths lie, and how the major topics are linked.
Persistence measures how dominant and stable a peak is. High-persistence peaks represent deeply established institutional focus; low-persistence peaks may represent emerging or peripheral topics. Persistence is what lets a reader distinguish structural signal from incidental noise in a large corpus.
Entity Mapping locates people, organizations, and cases precisely within the terrain. Every entity occupies a position; an Entity Dossier compiles that position into a full structural portrait: the peaks the entity sits near, the corridors it participates in, the other entities in its topological neighborhood, and the documents it appears in.
Footprints are the structural imprint of a scoped document set projected back onto the terrain. A footprint shows where a selection concentrates, how it spreads, and which regions it touches. Bundles are chosen groupings of peaks treated as a single analytic unit, useful for scoped investigation across multiple terrain features at once.
Terrain Movement captures change over time as the live corpus grows. When an institution shifts priorities, when a new topic emerges, when an existing focus contracts, the terrain updates and the movement becomes visible as structural change rather than as a list of new documents.
Every one of these is a first-class object. You can navigate to a pass and ask what is in it. You can open a corridor and read the documents that bridge two peaks. You can pull an entity dossier scoped to a specific community. None of this is possible with retrieval, clustering, or projection alone.
Before the vocabulary catches up
Conventional retrieval is a weather question: is it raining in Chicago? You get an answer for the place you asked about. A Semantic Terrain is a weather map: it shows the whole system at once, and the storm forming over Kansas is visible whether or not anyone asked about Kansas.
This matters because structural change in a corpus does not announce itself in queries. A new enforcement priority, an emerging threat category, a shifting institutional focus: these begin as geometric changes in the document body long before they are named in reporting or surfaced in analyst questions. A query-first system cannot see them; no one has yet formed the query that would retrieve them. A Semantic Terrain surfaces them as structural change in the geography, whether or not anyone is watching on any given day.
New peaks can emerge before anyone has articulated the topic in a query. Corridors can form between regions that were previously disconnected. Communities can split, merge, or drift. Each of these movements is a signal available to a reader of the terrain and invisible to a reader of queries.
This is why the live DOJ Semantic Terrain at cainc.semanticgaps.com updates as new press releases are published. The terrain is not a static map. It is a continuously updated reading of an institution's structural state, and the changes in that state are visible in the geography before they appear in the vocabulary.
Terrain-Augmented Generation
Once a corpus has a computed geography, a different class of retrieval becomes possible. Terrain-Augmented Generation, or TAG, is a retrieval and generation paradigm in which the model operates over terrain structures (peaks, passes, corridors, communities, bundles, footprints) rather than over document chunks alone. Documents remain the evidence base. But retrieval is no longer a flat similarity search against a query vector; it is navigation across structural objects.
A TAG system can answer questions RAG cannot, because TAG has access to information RAG does not compute: where a query sits in the terrain, which peaks neighbor that position, which corridors lead outward, which communities the query intersects, whether the relevant region is high-persistence or emergent, and where the structural boundaries of the answer actually lie.
TAG is the natural retrieval paradigm for a corpus that has been read as geography.
Key differences at a glance
| Dimension | RAG | Clustering (K-means, HDBSCAN) | Scatterplot (t-SNE, UMAP) | Semantic Terrain (CAINC) |
|---|---|---|---|---|
| Primary output | Ranked passages matching a query | Flat list of group labels | 2D projection of points | Navigable topological geography |
| Requires a query? | Yes, reactive to user input | No, but output is query-agnostic | No | No, the corpus is read as a whole |
| Represents the corpus as a whole? | No, treats it as independent chunks | Partial, groups without spatial relation | Partial, points without structure | Yes, as a continuous scalar field |
| Has transition zones between regions? | No | No, transitions are noise or absorbed | No, gaps are empty pixels | Yes: passes, corridors, contours |
| Supports structural change detection over time? | No | Unstable across re-runs | Unstable across re-runs | Yes, terrain movement is a first-class signal |
| Can surface what you did not know to ask? | No | No | No | Yes |
Why the distinction is a new category
The old pattern is familiar: search the corpus, cluster the corpus, visualize the corpus. The new pattern is different. Compute the corpus as geography. Read the geography. Navigate the terrain. Extract intelligence from the shape itself.
A Semantic Terrain is not a prettier chart, not a branding term for embeddings, and not a renamed cluster view. It is a new category of artifact, produced by a new category of instrument.
RAG tells you what was retrieved. Clustering tells you what belongs together. Scatterplots show where points landed. A Semantic Terrain tells you what the corpus structurally is, and what it is becoming.
At SemanticGaps, that terrain is generated by CAINC, our topological corpus intelligence instrument. The terrain is the reading. CAINC is the instrument. The practice of interpreting the reading, of extracting meaning from the shape of an institution's documents, is Corpus Intelligence.
Semantic gaps
SemanticGaps is named for the spaces between raw institutional output and the structural patterns hidden inside it: the gaps where meaning is not written but shaped. In terrain terms, these gaps have names now. They are the passes between peaks. The contours that separate communities. The corridors that bridge regions that no document explicitly connects. The footprints of scoped investigations that cross multiple terrain features at once.
Those gaps are where the most interesting intelligence lives. They are not visible to retrieval, because no document sits precisely in them. They are not visible to clustering, because they are not groups. They are not visible to scatterplots, because they are not points. They are visible only when the corpus is read as a terrain, and that is what CAINC is built to do.
The short version
RAG retrieves fragments. Clustering assigns labels. Scatterplots project points. None of them reads a corpus as a structural whole.
A Semantic Terrain does. It gives the corpus a geography you can navigate, a shape you can watch change, and a structure you can query without knowing what to ask. It enables Terrain-Augmented Generation, retrieval across shape rather than across fragments, and it is the foundational artifact of Corpus Intelligence.
That is the category. That is the paradigm.
Frequently Asked Questions
What is a Semantic Terrain?
A Semantic Terrain is a computed, navigable reading of the structural geography of a document corpus. It is generated by CAINC, the SemanticGaps instrument for topological corpus intelligence, and contains interpretable landforms (peaks, passes, corridors, contours, communities, and skeletons) extracted from the corpus itself.
What is CAINC?
CAINC is the SemanticGaps instrument that generates Semantic Terrains. It ingests a corpus, embeds it, and computes its structural geography as a scalar field from which topological features are extracted. The name comes from the Welsh word for branch. It is not an acronym.
How is a Semantic Terrain different from RAG?
RAG retrieves evidence relevant to a specific query. A Semantic Terrain computes the structure of the entire corpus without needing a query. RAG answers questions a user already knows to ask. A Semantic Terrain surfaces what the corpus contains, how it is organized, and what is changing, including regions and emergences the user had no prior reason to query.
How is a Semantic Terrain different from a scatterplot of embeddings?
A scatterplot is a two-dimensional projection of embedding vectors. Peer-reviewed research has shown that the distances and cluster shapes in t-SNE and UMAP projections are frequently distorted. A Semantic Terrain is a computed structural reading with mathematically grounded features (peaks, passes, corridors, contours) that can be navigated and queried as first-class objects.
How is a Semantic Terrain different from clustering?
Clustering assigns each document to a group label. A Semantic Terrain produces a geography, in which groups are positioned relative to one another, connected by corridors, separated by contours, and bridged through passes. Clustering tells you what belongs together. A Semantic Terrain tells you how the belonging is arranged in space.
What is Terrain-Augmented Generation (TAG)?
TAG is a retrieval and generation paradigm in which a model navigates the Semantic Terrain of a corpus rather than retrieving document chunks alone. Retrieval operates over terrain objects (peaks, passes, corridors, communities, bundles, and footprints) with documents serving as the evidence base underneath.
What is Corpus Intelligence?
Corpus Intelligence is intelligence derived from the shape and movement of large document bodies, rather than from individual documents read one at a time. It is the practice enabled by reading a Semantic Terrain.
Can I see a live Semantic Terrain?
Yes. The DOJ Semantic Terrain at cainc.semanticgaps.com is the first publicly available reading produced by CAINC. It is built on the full corpus of Department of Justice press releases and updates as new material is published.
What kind of corpus can CAINC read?
Any bounded document collection from a single institution or domain: regulatory filings, enforcement actions, published opinions, press releases, technical reports, policy documents. Each corpus has a shape, and CAINC makes that shape visible and navigable.
What is Terrain Movement?
Terrain Movement is change in the shape, peaks, or boundaries of a Semantic Terrain over time as the live corpus grows. It is the signal that something structural has shifted in the institution: a new focus emerging, an existing focus contracting, a boundary redrawing. It is often visible in the terrain before it is visible in conventional reporting.
References
- Barnett, S., Kurniawan, S., Thudumu, S., Brannelly, Z., & Abdelrazek, M. (2024). Seven Failure Points When Engineering a Retrieval Augmented Generation System. arXiv:2401.05856.
- Jeon, H., Park, J., Shin, S., & Seo, J. (2025). Stop Misusing t-SNE and UMAP for Visual Analytics. arXiv:2506.08725.
- Liu, Z., Ma, R., & Zhong, Y. (2025). Assessing and improving reliability of neighbor embedding methods: a map-continuity perspective. Nature Communications, 16, 5037.
- Campello, R. J. G. B., Moulavi, D., & Sander, J. (2013). Density-Based Clustering Based on Hierarchical Density Estimates. In Advances in Knowledge Discovery and Data Mining (PAKDD 2013).